
L’apprentissage automatique et ses biais
Notre quotidien est influencé par une série d’algorithmes, invisibles ou non. Mais qui sont ces algorithmes? Comment sont ils dévelopés?
Ont-ils des aspects cachés dont nous devrions nous méfier?
Dans cette série, nous nous concentrerons sur les algorithmes de l’apprentissage automatique, un sous-ensemble de l’intelligence artificielle.
Lis nos articles pour découvrir comment les biais sociétaux sont propagés et amplifiés à travers ces algorithmes.
Pour cette première partie, nous vous donnons les outils nécessaire pour comprendre les bases de l’apprentissage automatique, pour plus tard comprendre comment les biais s’y introduisent.
Qu’est-ce qu’un algorithme? [1]
L’algorithme est à l’informatique ce que la recette est à la cuisine. Ses ingrédients sont des données, il est écrit par des ingénieur·exs en informatique/informaticien·nexs, et à la place de bons petits plats, l’algorithme nous ressort des résultats digitaux.

Un exemple d’algorithme peut être simplement:

Un autre algorithme auquel vous êtes probablement confronté·exs de manière régulière est celui qui, par exemple, trie les articles que vous recherchez du moins cher au plus cher sur les sites de ventes en ligne. Cela peut paraitre assez simple. D’ailleurs, si je vous donne cette liste: [4, 7, 5, 78, 2] vous pouvez vous aussi la trier. Mais quand cette liste contient 100, 1000, 10000, etc. éléments, il est essentiel de trouver des moyens systématiques et beaucoup plus efficaces, et c’est là que les algorithmes sont les plus utiles: pour accomplir des taches que nous ne pourrions accomplir sans ordinateur, de par l’ordre de grandeur. Voici un exemple d’algorithme très simple de tri:


Une fois encore, l’algorithme que j’ai écrit ci-dessus n’est pas optimal, et laissera beaucoup, beaucoup, beaucoup de spam passer 😉
En bref, un algorithme, c’est un ensemble d’instructions (recette) que notre ordinateur suit lorsqu’on le lance. Il prend parfois des données (les ingrédients), qu’il manipule en vue de créer le résultat (les plats) qu’on lui a demandé de nous donner.
Le cas de l’apprentissage automatique [2, 3, 4]
L’apprentissage automatique, c’est un algorithme qui utilise des principes de statistiques (rappelez vous de notre article statistiques et société) et d’optimisations.
Plus spécifiquement, l’apprentissage automatique, consiste à entrainer des algorithmes qui apprennent/généralisent des données qu’on lui donne.
Il existe 3 grandes familles dans l’apprentissage automatique: l’apprentissage supervisé, l’apprentissage non supervisé, et l’apprentissage par renforcement. Pour comprendre les différences entre les trois, reprenons l’exemple des emails, et
d’un algorithme qui devrait comprendre quel email est un spam, et quel email n’est pas un spam.

L’apprentissage supervisé
Le principe de l’apprentissage supervisé est d’entrainer un algorithme en lui donnant une série d’observations qui sont étiquetées (par des humains) de manière à ce que l’algorithme comprenne ce que cette observation représente.
Dans notre exemple, l’algorithme recevrait une série d’emails (observations) associés à leur étiquette: spam ou non spam.

Le principe est de mimiquer la manière dont on apprend, par exemple, ce qu’est la différence entre une courgette et un concombre: on en voit lorsque l’on en achète au supermarché (observations), et lorsque l’on en achète un/une, l’étiquette sur la caisse dans laquelle nous prenons notre légume fait littéralement office d’étiquette. Au fur et à mesure, différencier les deux légumes devient donc plus facile.
L’apprentissage non supervisé
Dans l’apprentissage non supervisé, il n’y a pas d’étiquettes. L’algorithme reçoit une série d’observation, et il est de son devoir de mettre toutes les choses qui se ressemblent ensemble, et que les choses qui ne se ressemblent pas soient dans des groupes différents.
Dans notre exemple, l’algorithme reçoit une série d’email, qu’elle va classer en différentes catégories. L’étiquette de cette catégorie est alors déterminée par un humain, et/ou par un autre algorithme (supervisé cette fois-ci).
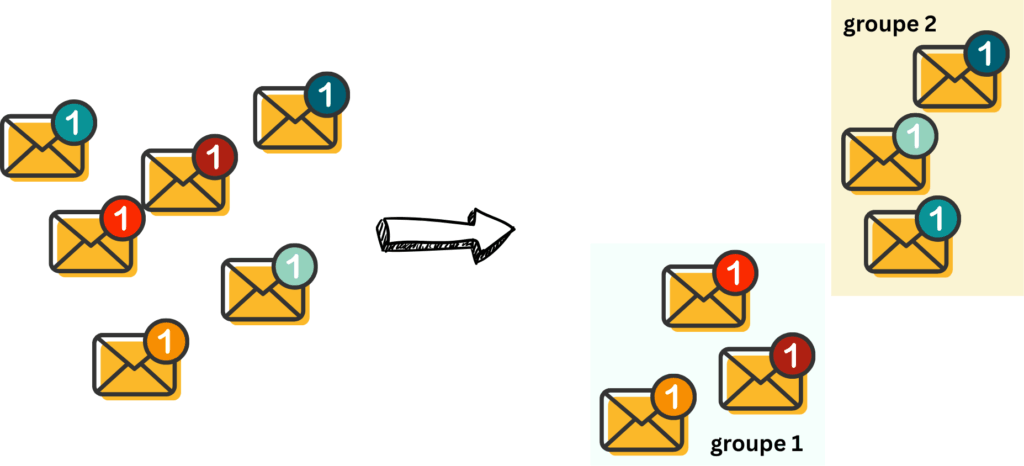
Naturellement, si vous aimez prendre beaucoup de photos en vacances, il est possible que en revenant, vous créiez des dossiers différents pour différents évènement, différentes catégories de photos sans que quelqu’un vous donnes des instructions quant à la manière de créer ces groupes.
L’apprentissage par renforcement
L’apprentissage par renforcement consiste à laisser un algorithme explorer “un monde” en imitant un humain. Lorsque l’algorithme rencontre quelque chose qu’il ne devrait pas être en train d’explorer, l’algorithme est puni. Lorsqu’il explore une partie du monde qu’il est censé explorer, il est récompensé.
Par exemple, on pourrait laisser un algorithme imiter un humain lisant ces emails. S’il lit un spam, il est puni, s’il lit un email d’un contact existant, il est récompensé (les récompenses et punitions sont pré-déterminées, et étiquetées). Il pourra ainsi apprendre ce qu’est un spam ou non par lui même.

Ce mode d’apprentissage mimique les situations où les enfants sont puni·exs lorsqu’iels font des bêtises, et sont récompensé·exs lorsqu’iels réussissent quelque chose (par exemple à l’école).
Dans le reste de cet article, nous nous concentrerons sur l’apprentissage supervisé, principalement de la classification
La classification
Principe
Comme son nom l’indique, la classification consiste à assigner à chaque observation sa bonne étiquette: assigner à une photo si elle représente un chat ou un chien, assigner à une personne si elle risque de récidiver ou non, assigner à un email si c’est un spam ou non, assigner à une recette si elle est saine ou non, etc. En d’autre terme, elle classe!
Comme mentionné ci-dessus, pour apprendre, l’algorithme doit s’entrainer. Reprenons l’exemple de nos recettes.
Nos observations seront les ingrédients, nos étiquettes sont les cakes, et nos algorithmes sont les recettes.
Un algorithme classique est l’équivalent d’une recette normale, telle qu’on peut les retrouver sur marmitton. Il exécute exactement ce qu’on lui a demandé de faire.
Un algorithme d’apprentissage automatique apprend. L’équivalent est donc une recette où le cuisinier doit apprendre les quantités d’ingrédients, ou l’ordre dans lequel les ingrédients doivent être mélangés/assemblés/cuits.
Pour s’entrainer (trouver les quantités optimales de chaque ingrédients, ainsi que l’ordre dans lequel ils doivent être incorporés), l’algorithme d’apprentissage automatique (recette incomplète) reçoit une série d’observations (le type d’ingrédients à utiliser) et d’étiquettes (le résultat optimal auquel on aimerait arriver).

Entrainement
Au début de l’entrainement, l’algorithme d’apprentissage automatique commencera par une recette aléatoire, qu’elle appliquera à tous les ingrédients. Elle comparera ensuite les cakes obtenus avec cette recette (prédictions), et les comparera avec les cakes originaux (étiquettes).

L’algorithme utilisera ensuite un processus que l’on appelle backpropagation [7] pour ajuster la recette, faisant en sorte de réduire la différence entre les cakes produits par la recette apprise (prédictions), et les cakes originaux (étiquettes). L’algorithme arrête d’apprendre lorsque les différences entre les cakes originaux et les cakes résultant des recettes apprises ne peuvent plus être réduites.
Sans rentrer dans les détails, parce que le point de départ est aléatoire, le point d’arrivée peut être différent aussi. C’est à dire qu’une même séance d’entrainement reproduite deux fois pourrait créer des recettes différentes, et cela peut dépendre de plein de facteurs différents, y compris la recette de début choisie aléatoirement.
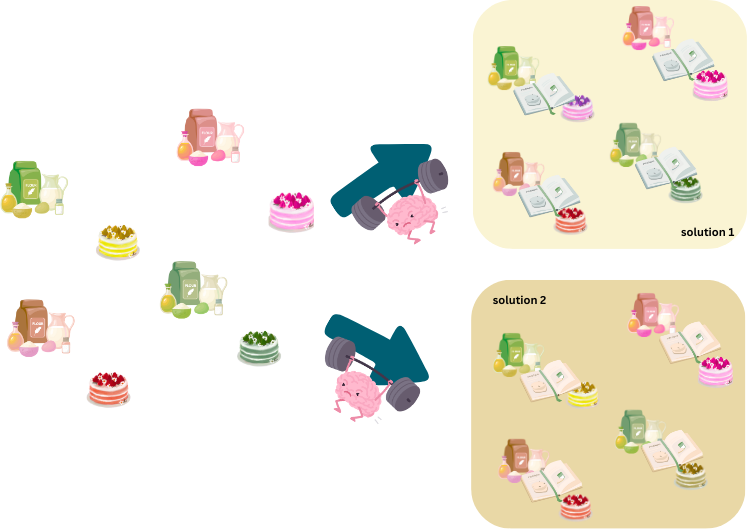
Test
La phase de test permet de vérifier que ce que l’algorithme a appris fonctionne bien. Pour cela, on va lui donner une liste d’ingrédients qu’il n’a jamais vu pendant l’entrainement. On mesure alors la vraie performance de l’algorithme d’apprentissage d’après les différences entre les nouveaux cakes (à partir d’ingrédients jamais vus), et les cakes originaux (auxquels ils auraient dû ressembler).
La régression logistique [5, 6]
Passons maintenant aux choses sérieuses, et faisons un petit de peu de maths (promis, aucun calcul mental)!
La régression logistique est un algorithme très utilisé en apprentissage automatique, mais aussi en psychologie, sciences sociales, etc. A la frontière des statistiques et de l’apprentissage automatique, elle est un très bon exemple d’introduction.
Revenons à l’exemple de notre algorithme de spam, et simplifions le problème. Représentons chaque email par une série de traits, et donnerons l’étiquette de -1 si c’est un spam, et 1 si ça ne l’est pas.
|
trait |
représentation mathématique |
|
La langue de l’email (dans la/les langues par laquelle/lesquelles nous avons l’habitude de correspondre) |
1 si c’est une langue que l’on parle, -1 si pas |
|
La longueur de l’email |
Le nombre de mots dans l’email |
|
La présence de demande d’argent |
1 si il y a une demande d’argent, 0 sinon |
|
L’heure de l’envoi |
1 si c’est pendant les heures de bureau, 0 sinon |
|
La présence de l’expéditeurice dans nos contacts |
1 si la personne se trouve dans nos contacts, 0 sinon |
Pour chaque trait, la régression logistique va créer un paramètre, qu’elle va initialiser à un nombre aléatoire (recette du début). Ces paramètres sont équivalent à la structure de la recette. L’algorithme va alors apprendre la valeur optimale des paramètres pour que un maximum d’emails soient correctement classés.
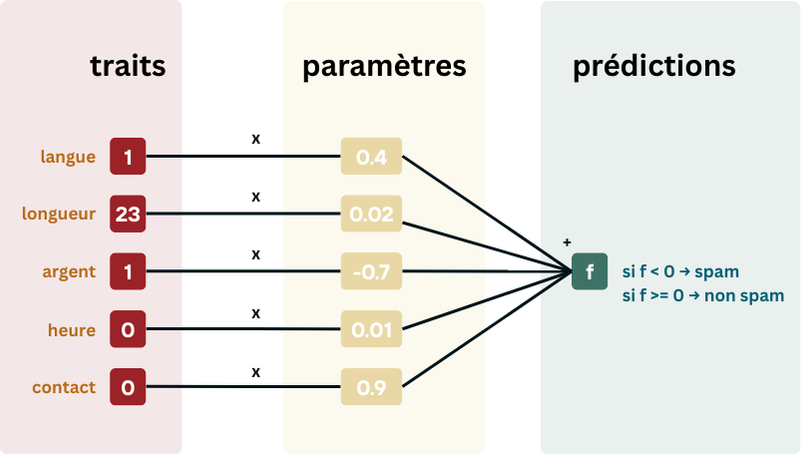
Les paramètres sont utilisés de la manière suivante: chaque trait va être multiplié par son paramètre correspondant, et tous ces produits vont être additionnés. Dans notre exemple ci-dessous, nous aurons donc: prédiction = 1 * a + 23 * b + 1 * c + 0 * d + 0 * e. Si notre prédiction est positive (>=0), nous considèrerons que l’email n’est pas un spam. S’il est negatif (<0) nous considèrerons que c’est un spam.
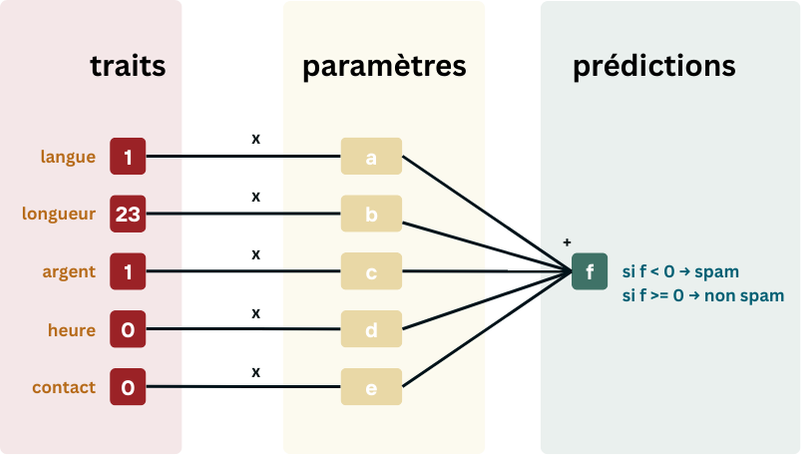
Après avoir vu beaucoup d’emails et leurs étiquettes, mettons que notre algorithme ai trouvés ces paramètres:
Et que nous avons ces trois emails:
“Coucou! Est-ce que tu pourrais demander à ta sœur si c’est elle qui a encore le tupperware que je vous avais donné il y a une semaine pour reprendre les lasagnes? Papa chéri”
“Hi! I’m from the US and I’m one of the richest men in the world. I’m actually Elon’s friend, and I’m looking for someone I can trust, so I can give them half of my fortune, which I don’t use currently. But first, to make the payment, I need your credit card number”
“Bonjour, c’est l’hôpital, nous n’avons rien trouvé sur vos analyses sanguines, recontactez nous dès que possible pour que l’on reprogramme quelques tests. Cordialement, Dr. S.”.
Quels scores l’algorithme ci-dessus leur donnerait? Lesquels seraient classifiés comme spam?
Indices: Commencez d’abord par transformer chaque email dans ses traits numériques, puis utilisez la formule prédiction= 1 * a + 23 * b + 1 * c + 0 * d + 0 * e, avec a = 0.4, b = 0.02, c = -0.7, d = 0.01, e =0.9.
En calculant les scores, vous vous êtes donc rendus compte que certains traits avaient plus d’importance dans le score final de prédiction que d’autres. Les traits dont les paramètres ont la plus grande valeur absolue sont donc plus importants pour déterminer si l’email est un spam ou non. Les traits dont le paramètre est négatif sont surement indicateurs de spam, tandis que les positifs sont indicateurs de non spam. (Il y a plusieurs nuances sur ces interprétations, donc il faut être prudent·ex, mais dans l’idée globale, c’est comme cela que ça se passe).
Classons des chats et des chiens!
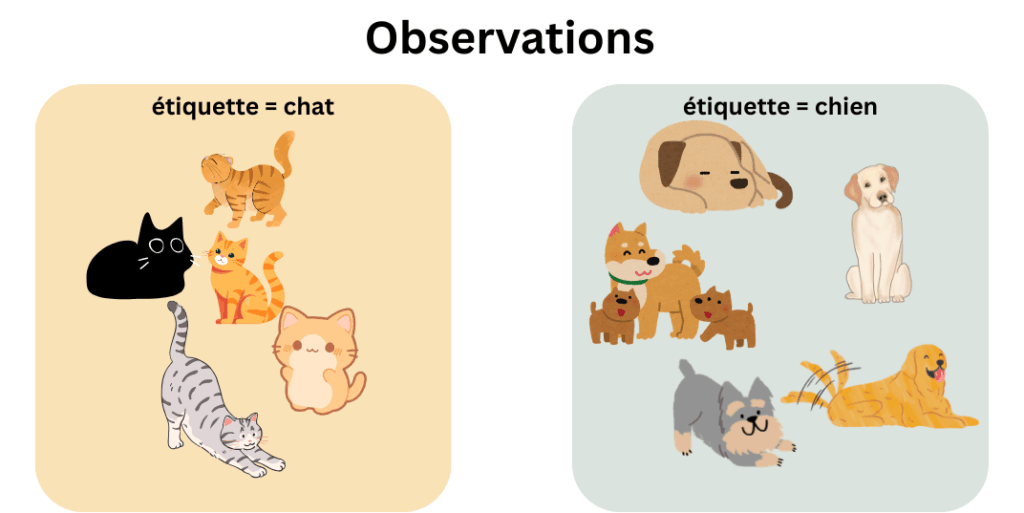
Terminons par un exemple simple: un algorithme qui voudrait classer des chats et des chiens. Pendant l’entrainement, l’algorithme voit ces images là:

Comment classifiera-t-il cet animal d’après vous?
Sources
[1] Introduction to algorithms. Lecture notes, MIT. Accessed April 27, 2025. https://ocw.mit.edu/courses/6-006-introduction-to-algorithms-spring-2020/477c78e0af2df61fa205bcc6cb613ceb_MIT6_006S20_lec1.pdf
[2] Lecture Machine Learning I. Lecture notes, KTH Royal Institute of Technology. Accessed April 27, 2025. https://www.kth.se/social/files/57398ec0f276541974919cc5/Lecture%20Machine%20Learning%20I.pdf.
[3] Machine Learning I. Lecture notes, EPFL Ecole Polytechnique Fédérale de Lausann. Accessed April 27, 2025. ML_course/lectures/01 at main · epfml/ML_course
[4] Lecture Machine Learning. Lecture notes, Harvard. Accessed April 27, 2025. https://github.com/harvard-ml-courses/cs181-textbook/blob/master/Textbook.pdf
[5] Cox, D. R. (1958). The regression analysis of binary sequences (with discussion). Journal of the Royal Statistical Society: Series B (Methodological), 20(2), 215–242.
[6] Werbos, P. J. (1974). Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. PhD dissertation, Harvard University.
[7] Linnainmaa, Seppo (1970). The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors (Masters) (in Finnish). University of Helsinki. pp. 6–7.