![[L’intelligence Artificielle et ses Biais] Episode 2: Erreurs de Classification](https://racism-search.be/wp-content/uploads/2025/06/Analyse-LEs-Outils-du-politique-pdf.jpg)
[L’intelligence Artificielle et ses Biais] Episode 2: Erreurs de Classification
L’apprentissage automatique et ses biais
Dans cet article, nous explorons les marges d’erreurs des algorithmes d’apprentissage automatique, et comment ces marges d’erreurs, inévitables, peuvent mener à la propagation de biais systémiques.
Si vous n’avez pas encore lu notre article d’introduction, jetez-y un coup d’oeil, nous utiliserons les mêmes analogies et le même vocabulaire.
Idée : Si vous n’avez pas encore lu notre article d’introduction, jetez-y un coup d’œil : nous y introduisons les analogies et le vocabulaire utilisés dans cette partie 2 de l’article.
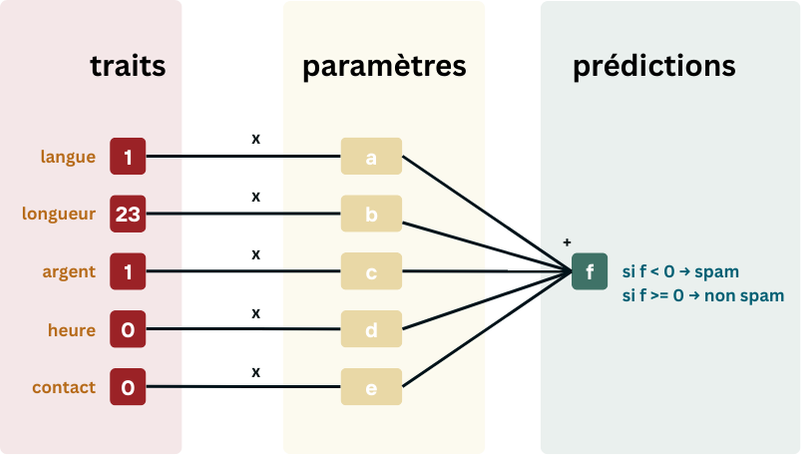
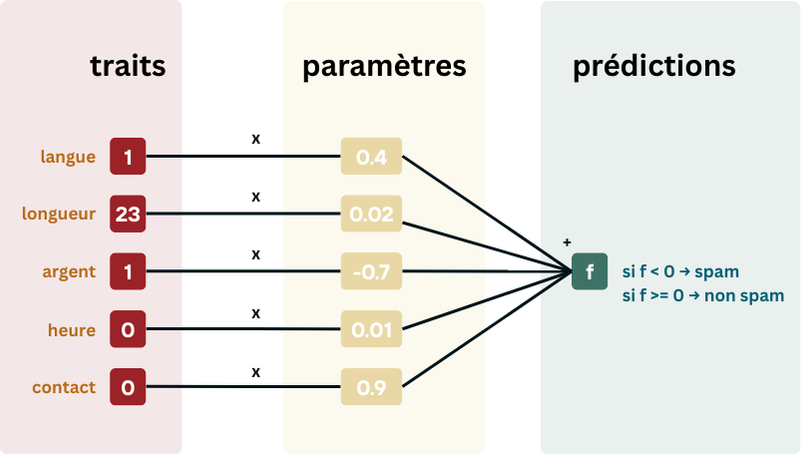
Qu’est-ce qu’un algorithme? [1]
La perte est la “quantité” d’erreur que l’algorithme fait entre ses predictions et les étiquettes des observations. Seulement voilà, tout comme les humains, il est presqu’impossible pour un algorithme d’avoir une perte de 0. Et quand il en a une, de perte de 0, souvent, cela cache autre chose… Utilisons l’exemple que l’on vous a laissé à l’article précédent; un algorithme qui voudrait classer des chats et des chiens. Pendant l’entrainement, l’algorithme voit ces observations-ci:
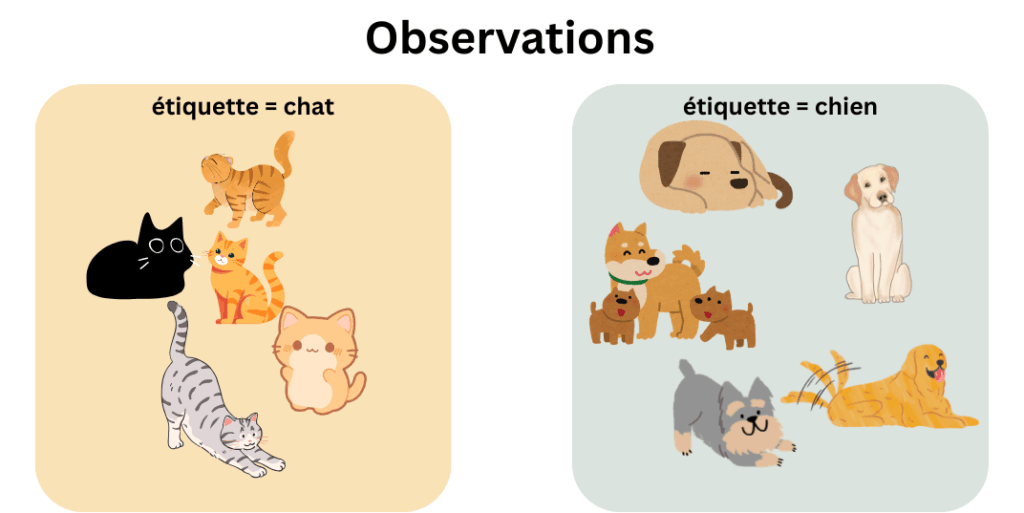
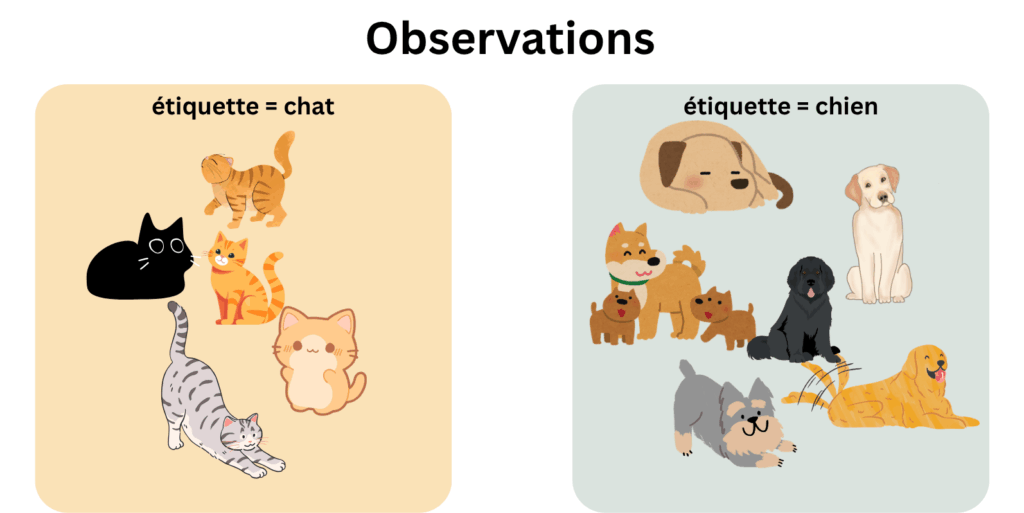
Comment classifiera-t-il George d’après vous?

Mettons que l’algorithme ait une marge d’erreur de 0, et prenne la couleur de la fourrure en compte. S’il apprend la formule : “si la fourrure est noire, alors c’est un chat”, il classifiera toujours le chat noir correctement, et n’aura aucune erreur de classification pour les autres animaux qui se trouvent dans le set d’entrainement.
Par conséquent, il ya une forte probabilité qu’il fasse le raccourci “si la fourrure est noire alors c’est un chat”, et que George soit pris pour un chat ( probabilité proche de 1). Il aura donc surajusté pendant l’entrainement. C’est à dire qu’il n’aura pas tenu en compte le fait que des chiens noirs puissent exister, meme s’ils n’ont pas été représentés dans les observations. Il n’a pas prévu l’imprévisible! Mais le peut-il?
La généralisation
Le set de données [2]
Idéalement, nous voudrions que le set d’observations que nous donnons à l’algorithme soit le plus complet possible. C’est à dire, qu’il soit un maximum exhaustif, et différent [2]. Pour illustrer nos propos, prenons une peinture:
Pour comprendre le sujet de notre peinture, nous voudrions que les “morceaux” de l’oeuvre que l’on arrive à voir à travers la foule dans le musée (observations) soient exhaustif, c’est à dire qu’il représente un maximum de détails pour que nous puissions comprendre et compléter le reste de l’oeuvre nous meme, dans notre imaginaire.

Cependant, avoir un échantillon exhaustif est assez compliqué. C’est pour ça qu’il est aussi important d’avoir des observations variées, pour récolter un maximum d’information sur le sujet de la peinture. Un manque de variété pourrait, par exemple, nous faire croire que ce tableau est en fait un jardin de rose, ou ne se constitue que de fleurs et de blasons flottants.

En bref, lorsque notre échantillon est à la fois exhaustif et varié, tout comme nous avec nos peintures, l’algorithme aura donc plus de facilité à anticiper et comprendre ce qui se passe en dehors des échantillons observés pendant l’entrainement! Si l’on ajoute donc un chien noir dans nos observations de base, l’algorithme ne se basera pas que sur la couleur pour se faire une opinion, et aura une plus petite erreur.
Les Traits [3]
Une manière plus simple d’endiguer le problème aurait été de ne pas utiliser la couleur de la fourrure comme trait. Dès lors, l’algorithme aurait été obligé de prendre d’autres traits tel que la taille, la forme des pattes, le poids, etc. de l’animal. Cela aurait pu cependant entrainer d’autres soucis, si il n’y a que des grands chats et des petits chiens, ou des chats obèses et des chiens malnouris.
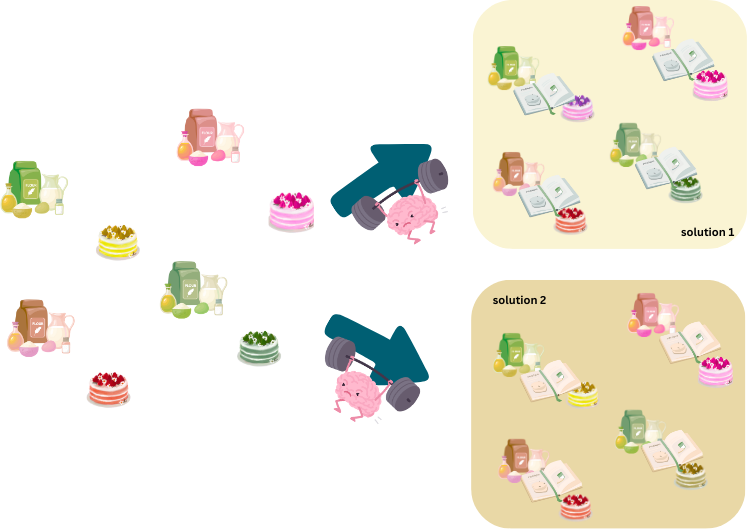
L’intuition derrière le choix des traits est que peu importe les observations que je reçois, je dois construire des traits qui me permettront de capturer les différences essentielles entre les deux groupes que j’essaye de classifier.
Dans l’exemple ci-dessous, mon algorithme généralise bien grace aux traits que j’ai choisi si, peu importe le pays dans lequel j’entraine mon algorithme, il est capable de reconnaitre les fruits et légumes du monde entier!

L’entrainement [4]
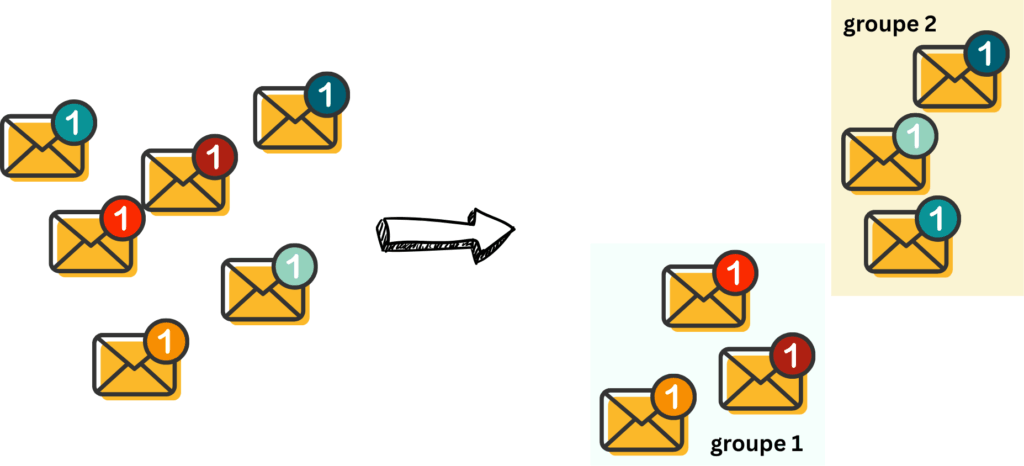
Un autre méchanisme pour s’assurer que l’algorithme ne sera pas surajusté et pourra bien généraliser, est de partitionner aléatoirement notre set d’entrainement en plusieurs parties.
Je m’explique. Imaginons nous avons toutes ces observations à notre disposition, pour entrainer l’algorithme. Si nous les utilisons toutes pour l’entrainement, nous ne pourrons pas savoir si notre algorithme marche bien pour classifier des animaux qu’il n’a pas encore vus. Alors que dans la réalité, les algorithmes que nous utilisons n’ont (parfois) pas été entrainés sur nos données en particulier, mais sur plein de données, qui, on l’espère, sont représentatives de la population.

On pourrait alors se dire que on pourrait garder une petite partie du set de données pour tester si l’algorithme généralise bien ou pas. Par exemple, dans l’exemple du dessous, on pourra se rendre compte qu’on a pas assez d’échantillons d’animaux noirs, ce qui pose un problème pour l’algorithme.

Mais si on choisit notre partition différemment, notre algorithme apprendra peut etre mieux..

Comment faire? En apprentissage automatique, il est courant d’utiliser la “cross validation”. C’est à dire d’utiliser différentes partitions. Une partition, c’est une manière de diviser un ensemble. Par exemple, dans mon ensemble (a, b, c, d, e), une partition possible est de faire (a, b, c) et (d, e) Une autre partition serait (a, d, e) et (b, c).
Pour chaque partition, on entrainera un algorithme sur la partie “entrainement” de la partition, et on calculera la perte sur la partie “test” de la partition.
Si la valeur des pertes sont différentes d’une partition à l’autre, alors on pourra dire que l’algorithme n’est pas très stable, et est très sensible au changement, et donc ne généralise pas forcément très bien. Il faudra donc bien faire attention à la manière de construire les partitions, ou récolter plus d’observations.
Si la valeur des pertes est stable, alors on peut dire que l’algorithme généralise bien.
Cas d’études [5, 6, 7]
Maintenant que vous en savez un peu plus sur les failles d’algorithmes d’apprentissage automatique, vous avez tous les outils pour analyser et comprendre comment certains algorithmes peuvent avoir un impact négatif sur les populations historiquement discriminées.
Prenons un algorithme fictif, qui prend, pour chaque élève, les traits suivants:
- les note au dernier examen de math
- le nombres d’heures de math par semaine que l’élève suit
- le type d’école (collège, lycée, catholique, libre, etc.)
- le nom de l’école (Athénée Royale de Vauban, Collège du Sacré-Coeur, Notre Dame des Champs, etc.)
- la ville (Charleroi, Bruxelles, Namur, Marcinelle, etc.)
et qui tente, à l’aide de ces traits, de prédire la note finale du prochain examen de math.
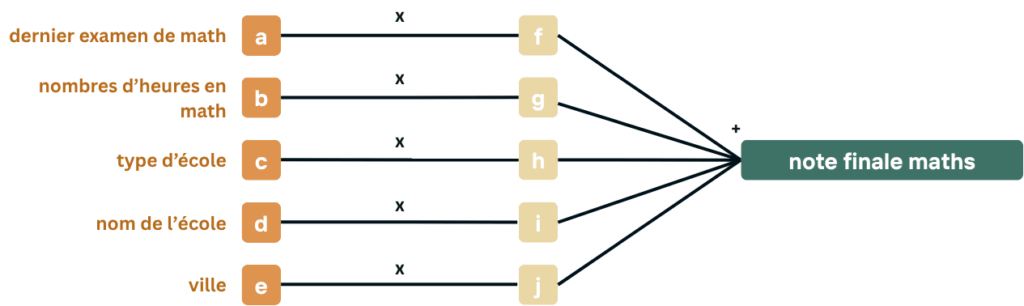
Quelle importance apporteriez vous à chaque traits?
L’exercice
Prenez du temps pour réfléchir aux questions suivantes:
- Quels traits jugeriez-vous importants pour la prédiction, si vous étiez vous-même enseignant·e·x·s?
- Selon vous, quels traits pourraient biaiser l’algorithme?
- Pourquoi les traits que vous avez choisis ci-dessus pourraient-ils créer des injustices?
La réalité
En tant qu’assistante de cours, j’aurais tendance à regarder la note du dernier examen de math ainsi que le nombre d’heures suivies en math pour jauger le niveau de en ? mathématique s ?d’un·ex élève. Vous aussi?
La réalité malheureusement, est parfois différente. En atteste le tristement célèbre cas de prédiction de note en Angleterrelors de la période COVID.
Pour postuler dans une université compétitive, il vous faudra souvent soumettre vos bulletins de notes, votre CV et une lettre de motivation. Les universités anglaises, elles, ont décidé d’être originales et de demander à vos professeur·exs de prédire les notes que vous obtiendrez à l’examen final (ce qui amène déjà plein de biais en soi meme).
Seulement voilà, :pendant le confinement, les professeur·exs ne pouvaient pas connaître leurs élèves. Donc, plutot que de ne pas utiliser le concept de notes prédites cette année là, l’Angleterre a décidé d’utiliser un algorithme d’apprentissage automatique pour faire les prédictions à la place des professeur·exs!
Et, roulements de tambours…
L’algorithme ne fonctionnait pas très bien. Sur le graphe ci-dessous, on peut voir que pour 58.7% des élèves, les notes prédites par les professeur·xs étaient similaires à celles prédites par l’algorithme. Cependant, l’algorithme prédisait des notes plus basses que celles des professeurs pour plus de 35% des élèves.

Sans surprises, cela a principalement impacté les minorités pauvres, et donc souvent racisées.
Pourquoi?
L’algorithme a pris en compte l’école dans laquelle l’élève avait été scolarisé·ex pour faire sa prédiction. Les élèves brillant·exs dans une école où la moyenne est un peu moins bonne que d’autres (généralement les écoles publiques) ont donc été systématiquement sous-coté·exs. Au contraire, les élèves des écoles privées, et donc mieux financées et beaucoup plus sélectives, ont elleux été surcoté·exs.
En bref, les élèves des écoles publiques étaient désavantagé·exs, et celleux des écoles privées, davantages avantagé·exs.
Quels biais systémiques cela entraîne-t-il, d’après vous?
Parce que cet algorithme a principalement impacté les élèves du public, et donc celleux venant d’un milieu socio-économique en général plus défavorisé il a discriminé davantages de personnes racisées que de personnes blanches, de par la répartition des richesses en Angleterre. Si personne n’avait trouvé ce biais, cet algorithme aurait donc pu saboter la carrière de nombreuses personnes racisées dès leur entrée dans la vie adulte tout en donnant un avantage à des personnes blanches, issues de milieu aisé, scolarisé·exs dans des écoles envoyant déjà beaucoup de leurs élèves dans des universités prestigieuses.
La propagation des biais
La propagation des biais ne doit pas etre inévitable. Pour endiguer ce phénomène, il est essentiel de travailler collectivement: programmeureuses/développeureuses/ingénieureuses, ainsi que sociologues, activistes, economistes, etc.
Dans le prochain article, nous introduirons un framework qui vous permettra d’analyser vous-même les risques que les algorithmes déployés peuvent engendrer, et nous analyserons plus de cas ensemble! N’hésitez pas à nous faire des suggestions de cas pour notre prochain article!
À bientôt!
Sources
[1] Lecture 3: Loss Functions and Optimization, Accessed May 5th, 2025. https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture3.pdf
[2] Mehrabi, Ninareh, et al. « A survey on bias and fairness in machine learning. » ACM computing surveys (CSUR) 54.6 (2021): 1-35.
[3] Hort, Max, et al. « Bias mitigation for machine learning classifiers: A comprehensive survey. » ACM Journal on Responsible Computing 1.2 (2024): 1-52.
[4] Lecture 4&5: Nonlinear Ridge Regression; Risk, Regularization, and cross-validation, Accessed May 5th, 2025 https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/lecture4.pdf
[5] A-levels: Dreams ruined by an algorithm, Accessed May 28th 2025, https://www.bbc.com/news/uk-northern-ireland-53767773
[6] Coronavirus: The story of the big U-turn of the summer, Accessed May 28th 2025 https://www.bbc.com/news/education-54103612
[7] A-levels and GCSEs: Student tells minister you’ve ruined my life, Accessed May 28th 2025, https://www.bbc.com/news/uk-53791736
![[L’intelligence Artificielle et ses Biais] Episode 1: Introduction à la Classification](https://racism-search.be/wp-content/uploads/2025/05/couverture-1080x675.jpg)